Key Points
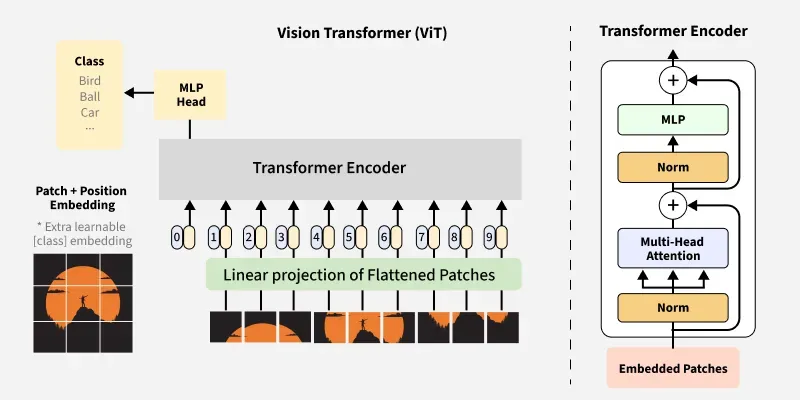
- ViT treats an image as a sequence of patches and applies self-attention across all patches.
- At larger dataset scale, ViTs often outperform CNNs on classification and transfer learning.
How ViT Differs from CNNs
Traditional CNNs build understanding through local convolutions, pooling, and hierarchical feature extraction. Vision Transformers start by splitting an image into fixed-size patches and embedding each patch as a token.
Self-attention then learns relationships between distant regions directly, which helps capture global context without stacking many convolution blocks.